DDR爱好者之家 Design By 杰米
为学习spark,虚拟机中开4台虚拟机安装spark3.0.0
底层hadoop集群已经安装好,见ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境
首先,去http://spark.apache.org/downloads.html下载对应安装包

解压
[hadoop@master ~]$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local [hadoop@master ~]$ cd /usr/local [hadoop@master /usr/local]$ sudo mv ./spark-3.0.0-bin-without-hadoop/ spark [hadoop@master /usr/local]$ sudo chown -R hadoop: ./spark
四个节点都添加环境变量
export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置spark
spark目录中的conf目录下cp ./conf/spark-env.sh.template ./conf/spark-env.sh后面添加
export SPARK_MASTER_IP=192.168.168.11 export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/usr/local/hadoop export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后配置work节点,cp ./conf/slaves.template ./conf/slaves修改为
master
slave1
slave2
slave3
写死JAVA_HOME,sbin/spark-config.sh最后添加
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
复制spark目录到其他节点
sudo scp -r /usr/local/spark/ slave1:/usr/local/ sudo scp -r /usr/local/spark/ slave2:/usr/local/ sudo scp -r /usr/local/spark/ slave3:/usr/local/ sudo chown -R hadoop ./spark/
...
启动集群
先启动hadoop集群/usr/local/hadoop/sbin/start-all.sh
然后启动spark集群

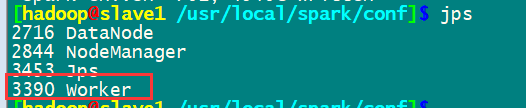
通过master8080端口监控

完成安装
DDR爱好者之家 Design By 杰米
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
DDR爱好者之家 Design By 杰米
暂无评论...
更新日志
2026年07月13日
2026年07月13日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]