DDR爱好者之家 Design By 杰米
需要汉化的演示软件是:Fiddler Everywhere
需要用到的汉化软件是:Notepad++、phpStudy、高铁采集器、TextReplace_v1.8(文本批量替换工具)
需要用到的汉化技术是:高铁采集器技术
Fiddler Everywhere这个软件已经诞生很久了,但网上一直都找不到汉化版本,可能是Fiddler Everywhere的汉化难度已经超出了所有人想象,它大部分需要翻译的内容都在Fiddler Everywhere\resources\app\out\WebServer\ClientApp\dist中的一个main.9c27a5768c5c6da2.js里面(红色字体的代表每个人在安装时候显示不同名称),别看这个js只有不超过5M大小的文件,它解压美化可能会达到35M。
使用Notepad++打开js文件,你会发现这个js把所有的内容都压缩在一行里面,如果你使用Radialix 3去汉化,可能会卡住,而且有可能导致文件的结构发生变化,导致软件无法正常打开。如果使用Notepad++去汉化,有可能会出现Notepad++卡死、或汉化容易出现错误,难以调试,又或者汉化太慢了,下面这节课的教程将是在汉化游戏或者软件中的一种重大的变革。
1、很多人都会使用高铁采集器,我这里就不细说了,简单说一下:将main.9c27a5768c5c6da2.js改名成1.js放入到phpStudy文件夹的WWW中,启动phpStudy软件;
2、将main.9c27a5768c5c6da2.js文件用Notepad++打开,你会发现有很多text:"开头的字符串,我这里为了方便就把它当成100个吧。
3、打开高铁采集器,将起始网址填写http://localhost/1.js,“起始网址就是内容网址”这里要点击一下,之后填写规则,正则提取,匹配内容填写text:"[参数]",组合结果填写text:"[参数1]",最后返回界面点击采集;
4、最后在采集里面直接复制,粘贴到一个.xlsx表格”文本“里面,如下图:
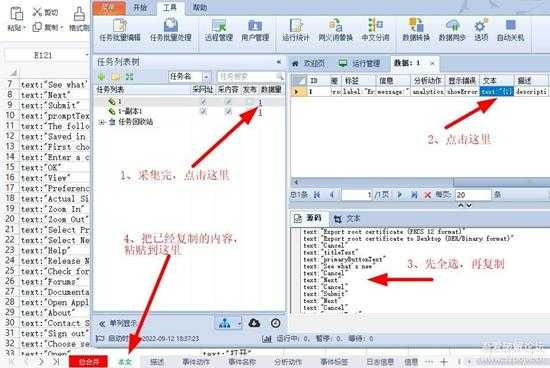
1.jpg
由于我第11课的教程已经讲解的非常清楚,表格字典是怎么制作的,下面就直接简单描述一下。
进入教程:
一、在将text:"与"替换成空字符之后,就把英文全部翻译成中文,最后把text:"把到B列,"放到D列,如下图:
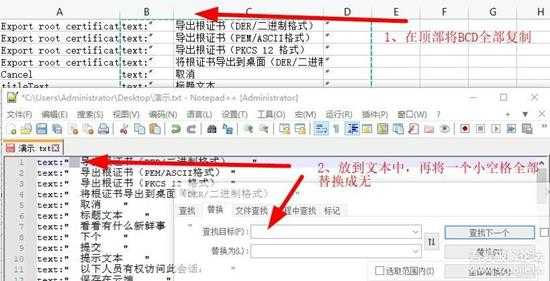
2.jpg
二、将已经替换好的内容全选,复制到表格的E列,字典就已经做好了,如下图:
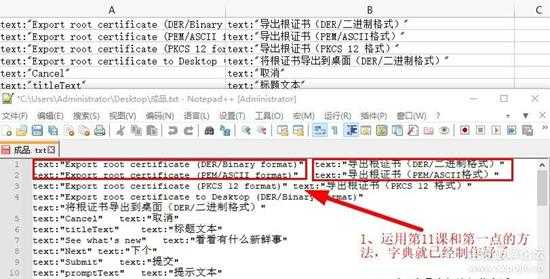
3.jpg
三、打开文本批量替换工具,将main.9c27a5768c5c6da2.js拖拉到左边,把”成品.txt“拖拉到右边(查看注意事项),再按照下图操作,最后在点击保存修改的之后,等待10几秒钟,如下图
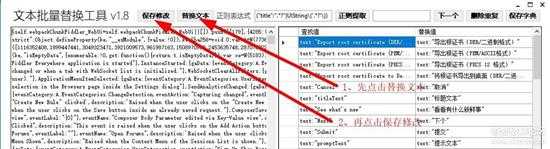
4.jpg
四、把已经汉化好的main.9c27a5768c5c6da2.js替换到Fiddler Everywhere\resources\app\out\WebServer\ClientApp\dist里面,看看汉化效果吧,如下图:
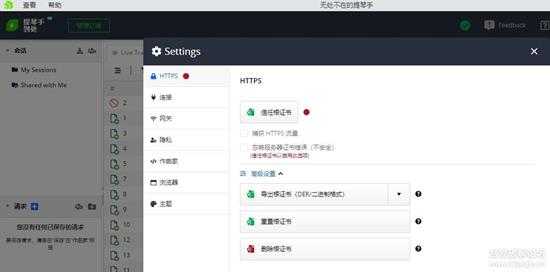
5.jpg
注意事项:
1、凡是提取到的符号和小写开头的英文字母(句子除外),都要在表格里面筛选删除,目的为了避免汉化错误。
2、凡是提取到连体英文都要删除,如FileDirectory,e与D之间是没有空格的,目的为了避免汉化错误。
3、在第三步的时候,应该将 成品.txt,转换成ANSI编码,查看我第10课的教程。
4、用高铁采集器提取到的不同规则不能放到一起,如text:"、description:"、logInfo(",目的可能增加制作字典难度。
5、Fiddler Everywhere软件还有一部分英文,在其它文件中,如dll格式的。本字典包已经汉化了main.9c27a5768c5c6da2.js文件80%英文内容。
 字典.zip2022-9-12 19:48 上传点击文件名下载附件
字典.zip2022-9-12 19:48 上传点击文件名下载附件售价: 1 CB吾爱币 [记录]
下载积分: 吾爱币 -1 CB
上一课【汉化教程】--第15课:解决jar程序汉化出现的乱码问题
DDR爱好者之家 Design By 杰米
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
DDR爱好者之家 Design By 杰米
暂无评论...
更新日志
2026年07月06日
2026年07月06日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]